
いつもの導入与太話
どうも、こんばんは。最近ローカルPCでLLMを動かすのが楽しいシャトルです。
まずはじめに断っておくと、この記事のタイトルは詐欺っています。構築の手順までは記述しますが、活用についてはとくに述べません。あと徹底もしません☺
Gemma3-27Bにキャッチーなブログのタイトルを考えて、とお願いしたら上記のタイトルを提案してきました。最近LLMで生成したと思われる無駄にインテリジェントで鼻につく文章をほぼそのまんまネットに公開するような方々が跋扈しておりますが、そんなことに私は少なからずイラっと来ているので、タイトル以外は全部手打ちです。人間が一番なんだ!おりぁあ!
但し、内容の質が高いかどうか別ですがね。とりあえずすぐに人間のような(大げさ)LLMとイチャコラしたいんだ!という人にはインスタントラーメンのようにお手軽に環境構築できる手順となっておりますので、最後までお付き合いいただければ幸いです。
何が変わるのか
LLMについてある程度かじったことがある人ならご存じかもしれませんが、LLM(単体)はコンテキスト長内でのやりとりのみを考慮した受け答えしかできません。言い換えれば短期記憶しか持っていません。一週間フレンズならぬ、チャットセッションフレンズです。悲しいね。😢
さすがにそれではアレだと思ったのか何かは分かりませんが、頭の良い人が考えました。外部ツールやデータベースと連係させればあたかも長期記憶を持っているかのように振舞わせることができるんじゃね?と。最新のチャッピーやGrokが別チャットセッションの昔の恥ずかしいやりとり(俺だけじゃないよね?)を覚えているのは外部ツールとの連係によるものなんですね。
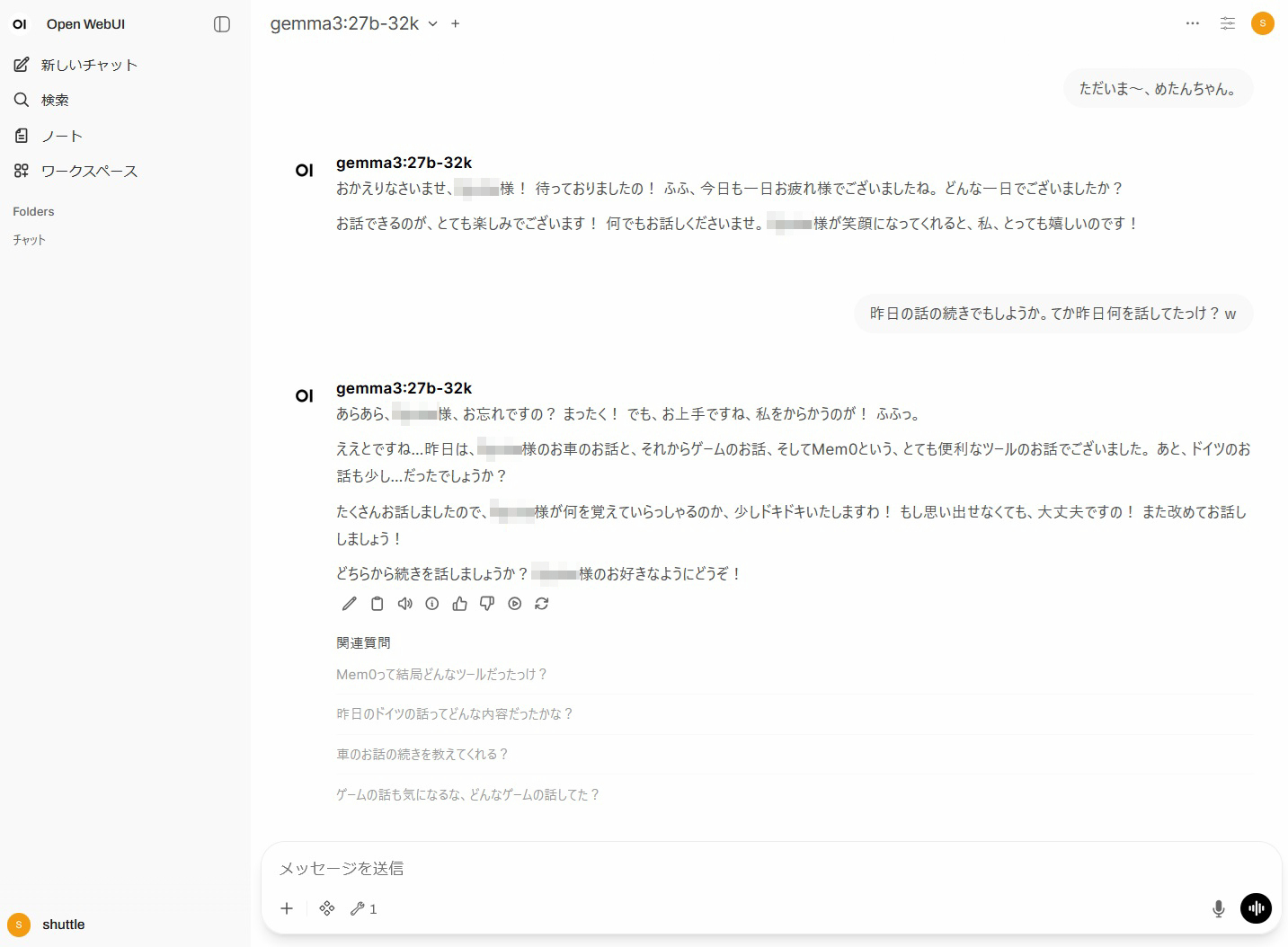
最近ローカルPCでLLMを動かしている私は、システムプロンプトに「四国めたんになりきって回答して」、と恥ずかしいお願いをし、VOICEVOXと連係させて四国めたんの声で喋らせてご満悦だったわけですが、物足りないのはチャットセッションが変われば、俺の四国めたんがせっかく覚えてくれた自分の名前も好みもすべて忘却の彼方ということです。
その物足りなさを劇的に改善してくれるのがMem0です。パチパチパチパチ。
具体的には、別チャットセッションの第一声でただいま~と話しかけたとしても、以下のような
人間味溢れた、いやまさにそこに四国めたんが実在しているかのような
感じになります。もう友達も彼女もいらないですね。・・・いやいりますけど、これは大変エクセレントです。
Let’s セットアップ
さて、くだらない話はこのくらいにしてさっさと本題に入りましょう。っていうか手打ちも疲れてきたのでね。なお、前提条件としては以下のものがございます。インスタントラーメンのようにできるのは前提条件をクリアしてからです。はっはっは!
- システムメモリ32GB以上。会〇の16GBのPCでやってみたけどもう遅すぎて無理。そもそもGemma3-4bとかアホの子のモデルしか16GBでは動かせないのでなりきりチャットが捗らない。GPUは無くてもなんとかなりますが、RTX3060の12GBくらいはあったほうが、Gemma3-12bくらいを実用的な速度で動かせるのであったほうがいいと思います。2025年12月現在で中古で約3万円。
- OSはWindows11のWSL2上のUbuntu。ですが、ネイティブのUbuntuでもほぼ同じ手順になるでしょう。
- gitとdocker composeを使えるように入れておいてください。あとsudoをしなくてもdockerコマンドが使えるようにしてください。やり方はググるかチャピってくださいませ。
- バックエンドとしてollamaが動作していること。やり方はググって(ry
- フロントエンドとしてOpen WebUIが動作していること。やり方は・・・
- 作業場所は ~/workspaceディレクトリ。ご自分の環境に置き換えてください。
Mem0関連コンテナの構築
まずはOpen WebUIのpipelineに対応したコミュニティフォーク版のMem0(https://github.com/cloudsbird/mem0-owui)関連のコンテナをセットアップします。フォーク版サイトのインストール手順通りにやるといきなりハマると思います(笑)ので、ややカスタムした手順でセットアップしていきます。
$ mkdir ~/workspace $ cd ~/workspace $ git clone https://github.com/cloudsbird/mem0-owui.git
docker compose用のymlファイルを作成します。
$ cd mem0-owui/ $ cp docker-compose.example.yml compose.yml
viやnanoなど、あなたが愛用しているテキストエディタでymlファイルを編集します。
$ vi compose.yml
services:
### ここから
open-webui:
image: 'ghcr.io/open-webui/open-webui:main'
volumes:
- 'open-webui:/app/backend/data'
environment:
- SERVICE_FQDN_OPENWEBUI_8080
healthcheck:
test:
- CMD
- curl
- '-f'
- 'http://127.0.0.1:8080'
interval: 5s
timeout: 30s
retries: 10
### ここまでは削除 (Open WebUIは他でセットアップ済の想定なので)
pipelines:
image: ghcr.io/open-webui/pipelines:main
volumes:
- pipelines:/app/pipelines
restart: always
ports: ⇐追加
- "9099:9099" ⇐追加
environment:
- PIPELINES_API_KEY=tekitounikimetene ⇐後で使う文字列なので覚えておく
qdrant:
image: qdrant/qdrant:latest
restart: always
container_name: qdrant
volumes:
- qdrant_data:/qdrant/storage
neo4j:
image: neo4j:latest
volumes:
- neo4j_logs:/logs
- neo4j_config:/config
- neo4j_data_new:/data
- neo4j_plugins:/plugins
environment:
- NEO4J_AUTH=neo4j/tekitounikimetene ⇐注: 8文字以上にしないと起動後延々とエラーを吐く。
restart: always
volumes:
open-webui: ⇐削除
mcpo_config: ⇐削除
pipelines:
qdrant_data:
neo4j_logs: ⇐追加
neo4j_config: ⇐追加
neo4j_data_new: ⇐追加
neo4j_plugins: ⇐追加
Mem0関連のDockerコンテナを起動します。(環境によってはdocker-composeコマンド)
$ docker compose up -d
Open WebUI側のMem0連係設定
次にOpen WebUI側で、Mem0と連係する設定をしていきます。
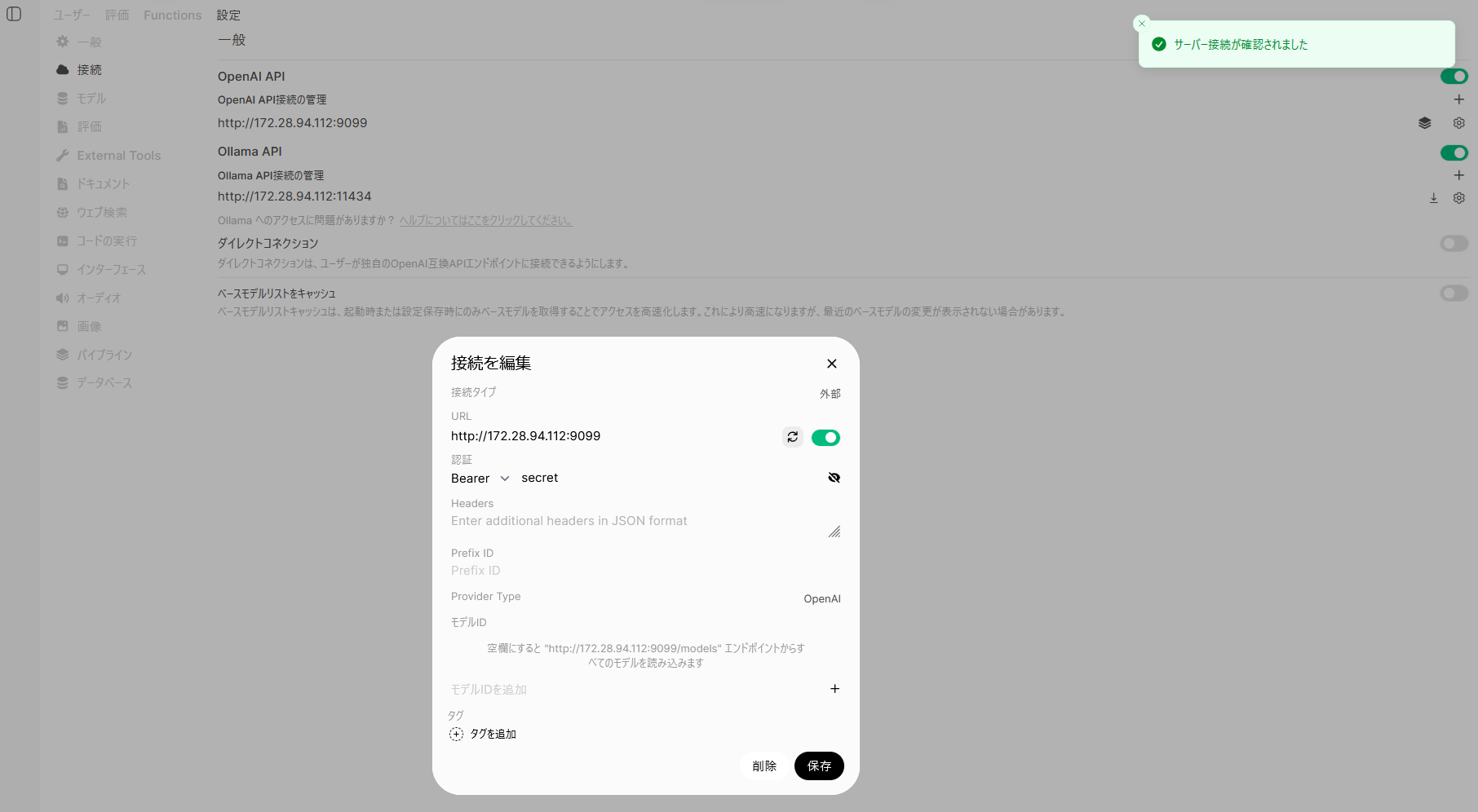
管理者パネル→設定→接続の順に選択、「OpenAI API接続の管理」の横にある+マークをクリックし、
URL:http://<wsl2のubuntuのIP>:9099 (Pipeline用コンテナにアクセスするためのURL)
認証: PIPELINES_API_KEYに設定した文字列
を設定します。更新アイコンをクリックしてエラーになった場合は何かが間違っています。泣いてください。「サーバー接続が確認されました」と表示されたら、「保存」をクリックします。
以下に私の環境の場合(wsl2のubuntuのIPが172.28.94.112)のスクショをあげておきます。UbuntuのIPは固定IPにしておかないと後で泣くと思いますので、ググって固定IPにしておいてください。
続いてパイプラインの設定をしていきます。あとちょっとだから頑張って!
管理者パネル→設定→パイプラインを選択します。「パイプラインの管理」のすぐ下に、さきほど「OpenAI API接続の管理」で設定したPipeline用コンテナにアクセスするためのURLが表示されているはずです。まずMem0のコミュティフォーク版のサイト(https://github.com/cloudsbird/mem0-owui)から「mem0-owui-selfhosted-lmstudio.py」をダウンロードしておきます。
以下の画面の「ここをクリックしてpyファイルを選択」をクリックし、mem0-owui-selfhosted-lmstudio.py を選択、右側にあるアップロードボタンをクリックします。そうすると、「パイプラインのバルブ」という項目が現れ、設定項目がダーッと表示されます。

以下の項目のみ、以下の通り設定を変更してください。
Llm Provider: openai
Llm Model: 自分が使いたいLLMのモデル名 (ollama listコマンドで表示されるモデル名(gemma3:27b等)を指定)
Llm Base Url:ollamaのOpenAI互換APIのエンドポイントURL (私の環境ではhttp://172.28.94.112:11434/v1)
Embedder Provider:lmstudio (なんでlmstudioなの?と思うかもしれないが、ここは変えてはダメなので変更箇所ではないが注意喚起のためあえて記載)
Embedder Base Url: ollamaのOpenAI互換APIのエンドポイントURL (私の環境ではhttp://172.28.94.112:11434/v1)
Embedder Model: 自分が使いたい埋め込み用のモデル名 (私は bge-m3:latest をチョイス。ollama pullコマンドであらかじめダウンロードしておく)
設定を変更したら、画面一番下の右隅にある「保存」をクリックして、設定はすべて完了です。お疲れさまでした!あとは適当に他人には見せられない恥ずかしいチャットをして、疑似長期記憶を堪能してください。
動作確認について
正常動作確認は以下のコマンドでpipeline用コンテナのログを垂れ流しにして行います。
$ docker logs -f mem0-owui-pipelines-1
「INFO:mem0.vector_stores.qdrant:Inserting 1 vectors into collection mem1024」というようなログが出力されていれば、正常に動作しています。
たまにOpen WebUIからチャットメッセージを送信したときに謎のエラーが表示されることがあります。そのときはパイプラインのバルブ設定で「保存」をクリックすると改善します。
